
分布式入门——基础理论
什么是CAP?
CAP 理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项
注意: CAP 是学术理论,并不是工程理论,它本身基于状态,基于瞬态,是一个描述性的理论,它并不解决工程问题,会舍弃很多现实世界的问题。比如网络的时长,比如节点内部的处理速度不一致,比如节点间存储方式和速度的不一致。它说的一致性就是客户端是否能拿到最新数据,它说的可用性就是允许客户端拿不到最新数据。
CAP的三个特性
C:数据一致性(Consistency)
简单理解:特指强一致性,即任何时刻都可以读到最近一次成功更新的副本数据(所有节点中的数据在任何时刻都保持一致)。当某个节点的数据发生变化后,所有其他节点都需要同步更新这个数据,确保数据始终一致
假设我们的分布式存储系统有两个节点,每个节点都包含了一部分需要被变化的数据。如果经过一次写请求后,两个节点都发生了数据变化。然后,读请求把这些变化后的数据都读取到了,我们就把这次数据修改称为数据发生了一致性变化
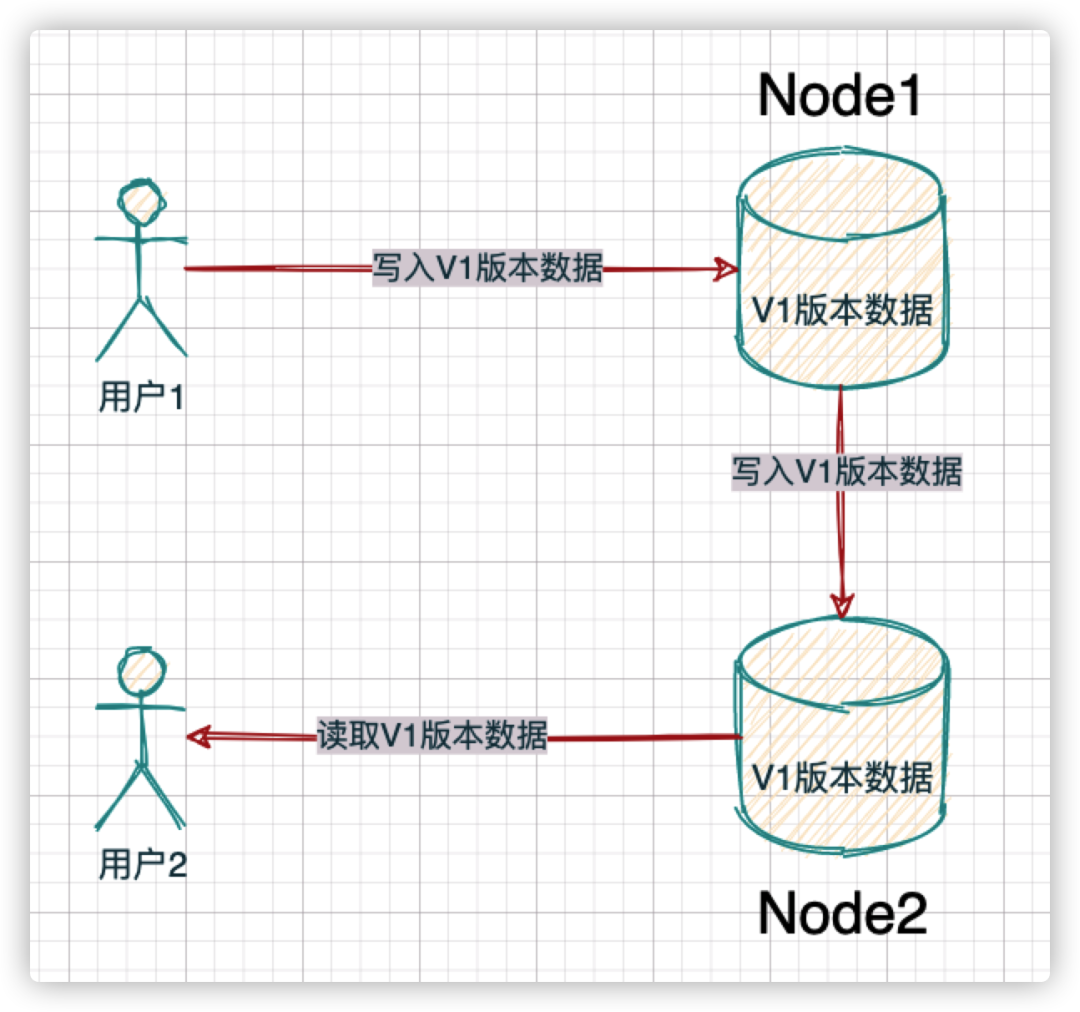
强一致性:如果系统内部发生了问题从而导致系统的节点无法发生一致性变化,此时,为了保证分布式系统对外的数据一致性,系统会选择不返回任何数据。
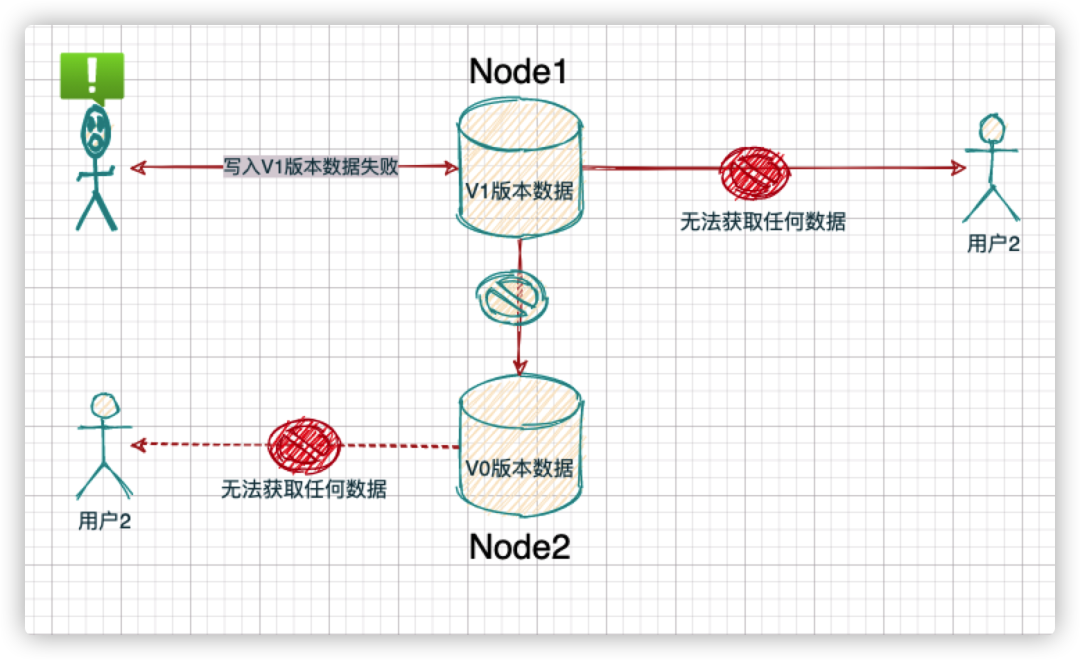
注意:CAP 定理是在说在某种状态下的选择,和实际工程的理论是有差别的。上面描述的一致性和 ACID 事务中的一致性是两回事。事务中的一致性包含了实际工程对状态的后续处理。但是 CAP 定理并不涉及到状态的后续处理,对于这些问题,后续出现了 BASE 理论等工程结论去处理
A:可用性(Availability)
简单理解:指的是即使系统中的一部分节点出现故障,整个系统仍然能够继续对外提供服务(部分节点的故障不会影响整体服务的响应)
可用性在是 CAP 里对结果的要求。它要求系统内的节点们接收到了无论是写请求还是读请求,都要能处理并给回响应结果。它有两点必须满足的条件:
- 返回结果必须在合理的时间以内,这个合理的时间是根据业务来定的。业务说必须 100 毫秒内返回,合理的时间就是 100 毫秒。如果业务定的 100 毫秒,结果却在 1 秒才返回,那么这个系统就不满足可用性。
- 需要系统内能正常接收请求的所有节点都返回结果。这包含了两重含义:
- 如果节点不能正常接收请求了,比如宕机了,系统崩溃了,而其他节点依然能正常接收请求,那么,我们说系统依然是可用的,也就是说,部分宕机没事,不影响可用性指标。
- 如果节点能正常接收请求,那么即使发现节点内部数据有问题,也必须返回结果,哪怕返回的结果是有问题的。比如,系统有两个节点,其中有一个节点数据是三天前的,另一个节点是两分钟前的。如果一个读请求跑到了包含了三天前数据的那个节点上,抱歉,这个节点不能拒绝,必须返回这个三天前的数据,即使它可能不太合理
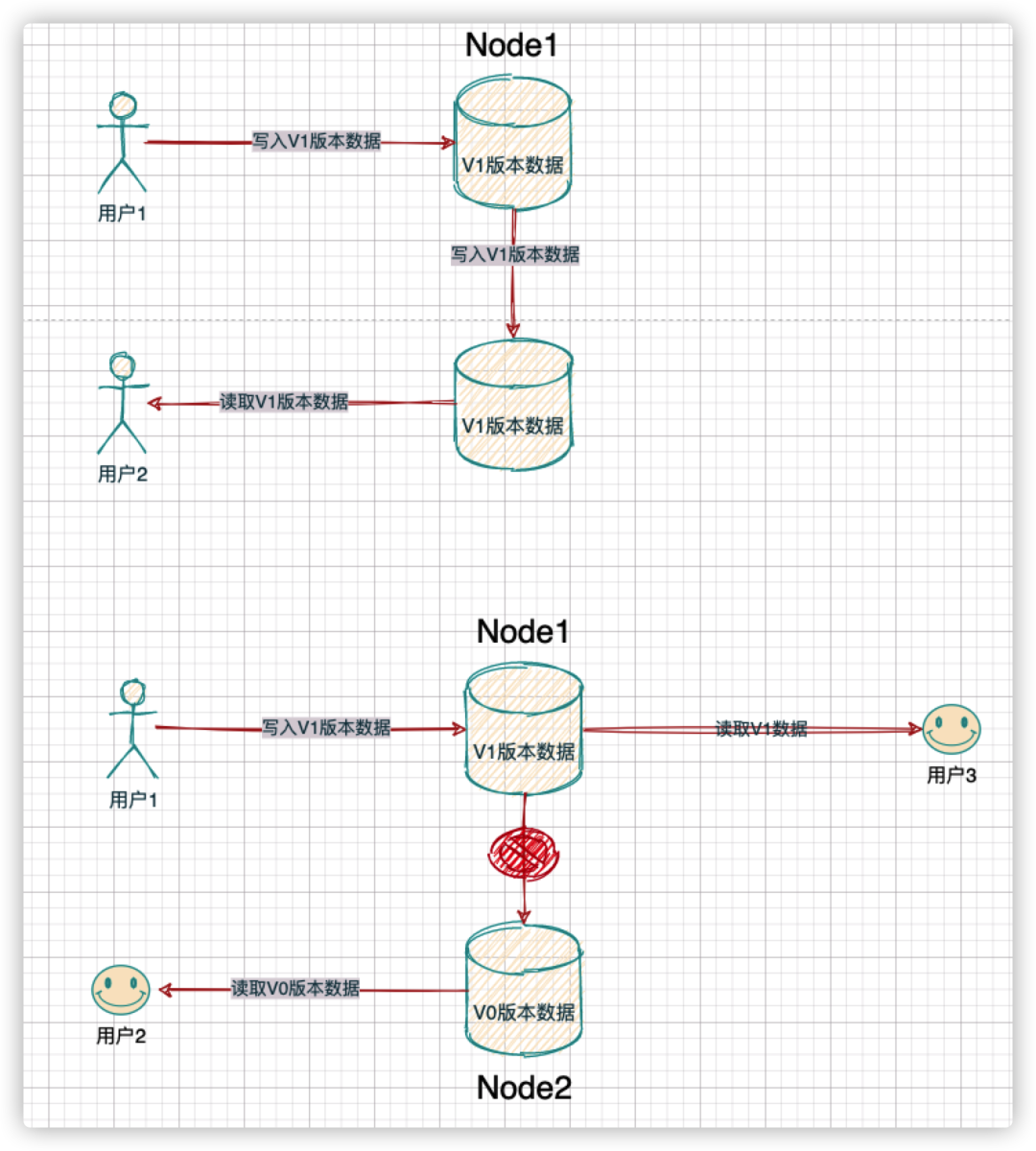
P:分区容忍性(Partition tolerance)
简单理解:指系统能够在网络分区的情况下还能提供服务
什么是网络分区?
- 分布式的存储系统会有很多的节点,这些节点都是通过网络进行通信。而网络是不可靠的,当节点和节点之间的通信出现了问题,此时,就称当前的分布式存储系统出现了分区。
- 值得一提的是,分区并不一定是由网络故障引起的,也可能是因为机器故障(如节点宕机,或路由器、交换机等底层网络设备出现了故障)。
- 总之,只要在分布式系统中,节点通信出现了问题,那么就出现了分区
什么是分区容忍性?
- 分区容忍性指如果出现了分区问题,我们的分布式存储系统也必须继续运行。不能因为出现了分区问题,整个分布式节点全部就熄火了,罢工了,不做事情了
A和P好像都是描述系统的可用性,它们有什么差别?
- A关注的是每个请求能否被响应(无论数据是否最新),是客户端视角的可用性,是对分布式系统结果的要求。
- P关注的是系统能否在网络分区时继续运行,是系统架构视角的容错能力,是对分布式系统前提的要求。
CAP的选择
为什么CAP只能满足其二?
如前文所述,P是分布式系统的前提要求,因为实际情况中网络分区是不可避免的。如果不选 P,一旦发生分区错误,整个分布式系统就完全无法使用了,这是不符合实际需求的
而在网络分区不可避免的情况下,一致性与可用性无法同时满足:
- 想满足一致性就需要等待到分区恢复,即牺牲了可用性
- 想满足可用性,就无法保证不同节点读取数据的一致性
所以,CAP的三选二,其实是二选一(C or A)
典型系统的CAP选择
- CP系统(牺牲A)
- 例子:ZooKeeper、HBase、传统数据库(如MySQL主从同步)。
- 场景:金融交易等对一致性要求极高的场景,允许部分节点在分区时不可用。
- AP系统(牺牲C)
- 例子:Cassandra、Dynamo、Redis Cluster。
- 场景:高可用优先的场景(如社交媒体),接受短暂的数据不一致。由于CAP 定理本身是没有考虑网络延迟的问题的(它认为一致性是立即生效的),但是,要保持一致性,是需要时间成本的,这就导致往往分布式系统多选择 AP 方式。
- CA系统(牺牲P)
- 例子:单机数据库(如单节点MySQL)。
- 场景:不适用于分布式环境,仅在网络绝对可靠的假设下成立。
CAP的一些注意点
C或A在没有网络分区时可以共存
CAP理论的核心限制是:在网络分区(节点间通信中断或延迟)时,系统必须在一致性和可用性之间二选一。
由此可见,CAP的核心矛盾仅在网络分区(P)发生时才被触发。所以,当网络正常(无分区)时,系统必须同时保证一致性(C)和可用性(A)。具体而言,系统既可以通过同步机制保证一致性,又能及时响应请求,保证可用性。此时C和A可以共存。
总而言之,当没有出现分区问题的时候,系统就应该有完美的数据一致性和可用性。
C和A的抉择是局部性的
当分区发生的时候,其实对一致性和可用性的抉择是局部性的,而不是针对整个系统的:可能是在一些子系统做一些抉择,甚至很可能只需要对某个事件或者数据,做一致性和可用性的抉择而已。
比如,当我们做一套支付系统的时候,会员的财务相关像账户余额,账务流水是必须强一致性的。这时候,你就要考虑选 C。但是,会员的名字,会员的支付设置就不必考虑强一致性,可以选择可用性 A。
CAP特性是一个范围,而非是与否的极端选择
CAP 理论的三种特性不是 Boolean 类型的,不是一致和不一致,可用和不可用,分区和没分区的这类二选一的选项。而是强一致性和弱一致性,高可用和低可用,高容错和低容错的范围变化:
- 一致性
- 强一致性:所有节点数据实时一致,但牺牲可用性。如ZooKeeper 的线性一致性
- 弱一致性:允许短暂不一致,但最终收敛。如DNS 系统的数据传播延迟可能长达数小时
- 可用性
- 完全可用:所有请求始终响应,如 AP 系统的无超时设计
- 部分可用:系统降级处理部分请求,如限流、熔断机制等服务降级机制
- 不可用:完全拒绝请求,如 CP 系统在分区时停止写入
- 分区容忍性
- 完全容错:系统能容忍任意规模的分区,如Cassandra 的多数据中心复制
- 部分容错:仅容忍短时间或小范围分区,如MongoDB 副本集容忍少数节点离线
- 无容错:依赖单点或同步网络,如单机 MySQL 无法应对网络中断
其他分布式理论
BASE理论
Base的核心思想:即使无法做到强一致性(Strong Consistency),但应用可以采用适合的方式达到最终一致性(Eventual Consistency)
BASE的概念
- BA(Basically Available,基本可用):当系统出现故障或意外情况时,允许放弃掉部分可用性,保证核心功能可用,例如大促时的服务降级策略等。
- S(Soft state,软状态):允许系统存在中间状态,并且该中间状态不会影响系统整体可用性。
- E(Eventually consistent,最终一致性):指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。即意味着中间状态,只会短暂存在,在一定时间后,肯定会变成最终状态。
Base理论的指导意义
BASE 中的基本可用指的是保障核心功能的基本可用,其实是做了“可用性”方面的妥协,比如:
- 系统访问压力较大的时候,关闭次要功能的展示,从而保证主流程的可用性,这也是我们常说的服务降级。
- 为了错开高峰期,网站会将预售商品的支付时间延后十到二十分钟,这就是流量削峰。
- 在抢购商品的时候,往往会在队列中等待处理,这也是常用的延迟队列。
软状态和最终一致性指的是允许系统中的数据存在中间状态,这同样是为了系统可用性而牺牲一段时间窗内的数据一致性,从而保证最终的数据一致性的做法
PACELC理论
CAP理论并不能很好的指导现实的系统架构:大部分情况下,系统分区都是平稳运行的,系统设计要权衡延迟与数据一致性的问题。为了保证数据一致性,读写的延迟必然升高,于是就有了PACELC理论
PACELC理论是对CAP定理的扩展与细化,旨在更细致地描述分布式系统在分区和无分区场景下的性能与一致性权衡
PACELC理论是建立在CAP理论之上的,二者都描述了一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)之间的约束与取舍。而PACELC理论则更进一步描述了即使在没有Partition的场景下,也存在Latency和Consistency之间的取舍,从而为分布式系统的Consistency模型提供了一个更为完整的理论依据
PAC-Else-LC:
- 分区时:PAC
- P:分区容忍性
- A:可用性
- C:一致性
- (Else)
- 无分区时:LC
- L:Latency,延迟
- C:Consistency,一致性
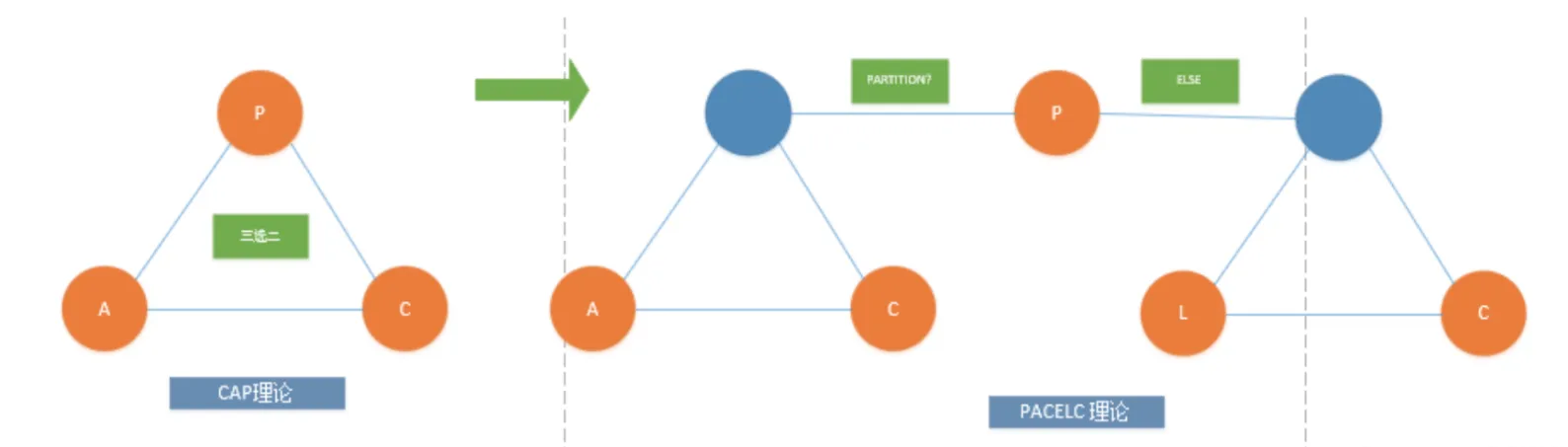
根据 PACELC 模型的定义,如果有网络分区产生,系统就必须在AP系统与CP系统之间做权衡(PAC),否则(Else)当系统运行在无网络分区的正常情况下,系统则需要在 L(延迟)和 C(一致性)之间取得平衡
NWR多数派理论
NWR是一种在分布式存储系统中用于控制一致性级别的一种策略
- N: 数据在系统中总共维护多少个副本。例如,N=3 表示数据被复制存储在不同的3个节点(服务器)上
- W:写操作被视为成功的最小副本数。只有当写操作成功更新了至少 W 个副本后,系统才会向客户端返回“写成功”
- R:读操作被视为成功的最小副本数。只有当读操作成功从至少 R 个副本读取到数据后,系统才会向客户端返回“读成功”
NWR分别设置不同的值时,将会产生不同的一致性效果。
W+R>N:整个系统对于客户端的请求能保证强一致性。- 因为写请求和读请求一定存在一个相交的副本,这个副本一定包含了最新的数据(它是成功写入的 W 个副本之一),而读操作也必定能从这个副本中读取到最新的数据
- 所以,即使其他副本上的数据可能暂时是旧的(由于网络延迟或节点故障),只要从这个重叠副本中读到最新值,就能确保该读操作返回的是最新数据
W+R<=N:整个系统对于客户端的请求则不能保证强一致性
NWR的一些配置示例
W = 1, R = 1, N > 1:写入最快(只需一个副本),读取最快(只需一个副本),但可能读到旧值(脏读),也可能丢失写入(如果唯一更新的副本后来故障了)。一致性最弱。W = 1, R = N:写入最快,但读取必须访问所有副本。读取能看到最新的写入,但读取延迟高、可用性低(一个读副本故障则读失败)。W = N, R = 1:如上面所述,强一致,但写入慢且可用性低。- 折中配置
W + R > N(例如N=3, W=2, R=2或N=3, W=3, R=2等)- 性能/延迟: 比
W=N, R=1延迟低(尤其是写)。 - 可用性: 可以容忍
N - W个写副本故障 和N - R个读副本故障。比W=N或R=N可用性更高。 - 一致性: 保证强读写一致性(总能读到最近一次成功写入的数据)
- 性能/延迟: 比
与CAP理论的联系
NWR是实践中实现AP系统时,控制**一致性(C)**的重要手段:
- 无分区时:
W + R > N能保证强读写一致性。 - 发生分区时:系统可能无法满足
W或R的要求,此时W和R值的选择直接决定了在分区场景下系统更倾向于A还是C





